Build an Unbannable Web Scraper: The Steps Most Tutorials Skip
How many "5-minute proxy setup for web scraping" tutorials have you watched?
Most of them say: buy a proxy, change a config, run it.
But what happens next?
IP banned. Requests rejected. Data collection stops.
What went wrong?
These tutorials only scratch the surface. They skip the critical steps that actually make a scraper "unbannable." This guide fills in those gaps.

1. The Step Most Tutorials Skip: Pick the Right Proxy Type
This is the most overlooked step.
Pick the wrong proxy type here, and no amount of tweaking will save you.
Residential vs Data Center Proxies
Type | Best For | Not Ideal For |
|---|---|---|
Residential | High-security sites (Amazon, Google, Facebook) | Low-security sites (overkill) |
Data Center | Low-security sites, testing environments | High-security sites (banned instantly) |
The rule of thumb:
Site has anti-bot measures → Use residential proxies
Site barely has any protection → Data center proxies work fine
Tight budget but tricky target → Still go residential. Getting banned costs more than saving money.
💡 Not sure which to pick? Start here: What Is a Proxy Server for Web Scraping? The Truth Nobody Tells You
Proxy Provider Selection Criteria
Getting the type right is just the start. You also need the right provider.
5 must-check metrics:
IP pool size: Bigger is better—at least 5M+ IPs
Success rate: 95%+ is the baseline
Geographic coverage: Must include your target countries/cities
Stealth level: Residential proxy ratio should be 80%+
Tech support: 24/7 availability, solid API docs
2. The Step Most Tutorials Skip: Configure Proxies Correctly
This one gets some attention, but the coverage is incomplete.
Basic Config: Format and Authentication
The core proxy config looks like this:
protocol://username:password@proxy_address:port
Two common protocols:
HTTP Proxy:
http://user123:password@gateway.ipipd.com:8080
SOCKS5 Proxy:
socks5://user123:password@gateway.ipipd.com:8080
The difference:
HTTP proxy: HTTP/HTTPS requests only
SOCKS5 proxy: All protocols, slightly faster
For most scraping jobs, HTTP proxy gets the job done.
Advanced Config: Connection Pool Management
Many people set up a single proxy and fire off requests one by one. Inefficient.
Do this instead: use a connection pool.
Core concepts:
Maintain multiple proxy connections at once
Reuse connections—avoid constant TCP handshakes
Pull available proxies from the pool automatically
Drop dead proxies automatically
This alone can boost your scraping efficiency by 3-5x.
Pro-Level Config: Proxy Grouping
Scraping multiple sites? Group your proxies by destination:
# Proxy grouping example proxy_groups = { 'amazon': ['proxy_1', 'proxy_2', 'proxy_3'], 'google': ['proxy_4', 'proxy_5', 'proxy_6'], 'facebook': ['proxy_7', 'proxy_8', 'proxy_9'] }
Benefits:
Different sites use different proxy pools—no cross-contamination
Customize rotation strategy per site
Easier to debug when something goes wrong
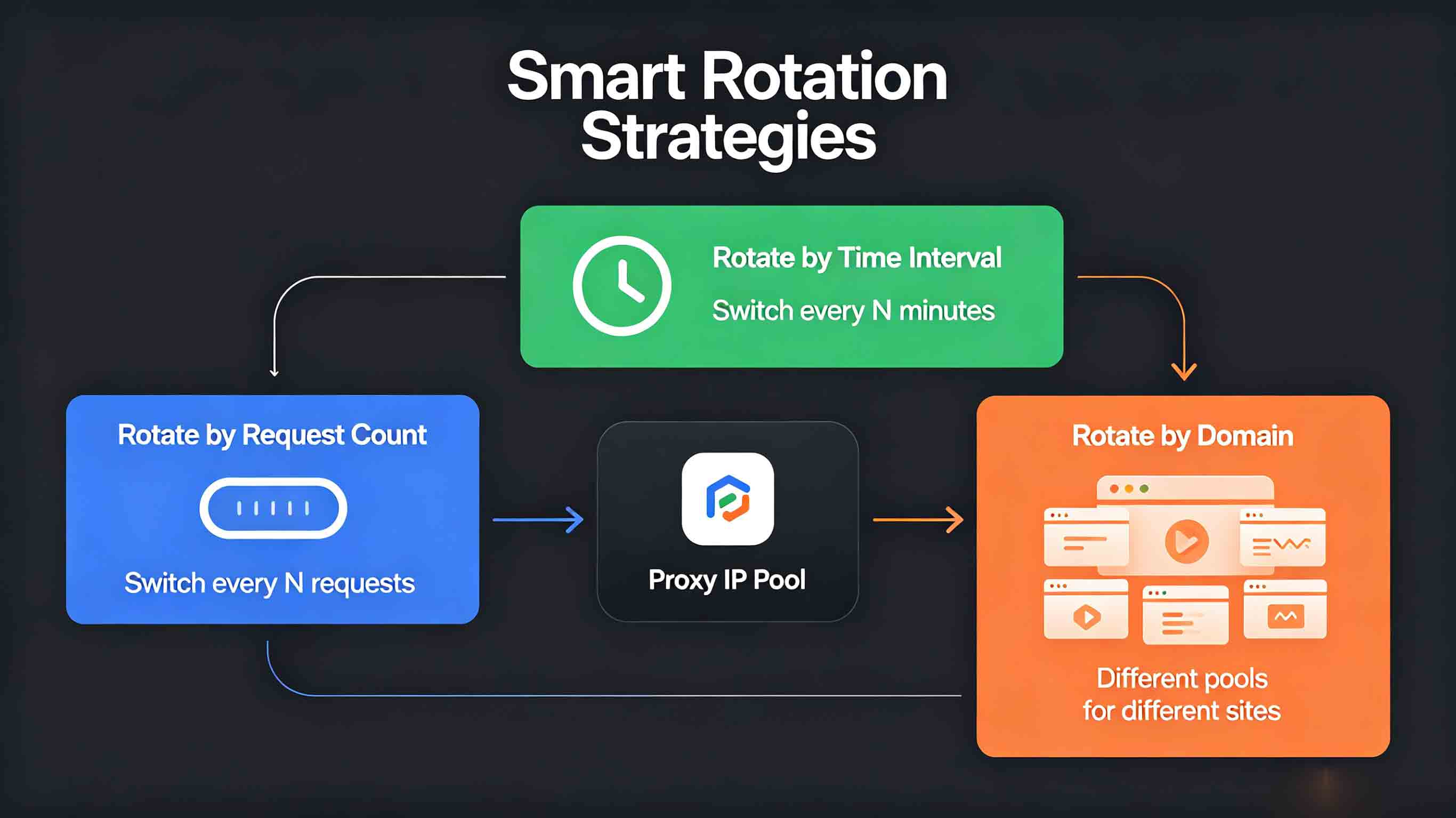
3. The Step Most Tutorials Skip: Smart Rotation Strategies
This is the core of keeping your scraper unbannable.
Why Does Rotation Matter So Much?
Picture this:
You have 100 IPs
Each IP sends 1,000 requests per day
You rotate once per day, so each IP hits 1,000 requests
Result: Day 2, most of those IPs are banned.
The right approach:
Each IP sends only 100 requests per day
Rotate to the next one when exhausted
Day 2, start fresh from IP #1
Ban rate drops from 90%+ down to under 5%.
Three Rotation Strategies
Strategy 1: Rotate by Request Count
Switch proxies every N requests.
Best for:
Stable, predictable collection volume
Tasks that need session persistence
# Example: rotate every 50 requests request_count = 0 switch_every = 50def get_proxy(): global request_count request_count += 1 if request_count % switch_every == 0: return rotate_to_next_proxy() return current_proxy
Strategy 2: Rotate by Time Interval
Switch to a fresh proxy every N minutes.
Best for:
Long-running collection jobs
Tasks that don't need session persistence
import time last_switch = time.time() switch_interval = 300 # 5 minutesdef check_rotation(): global last_switch if time.time() - last_switch > switch_interval: rotate_proxy() last_switch = time.time()
Strategy 3: Rotate by Domain
Different proxy pools for different target sites.
Best for:
Scraping multiple sites simultaneously
Need isolation between different scraping environments
def get_proxy_for_domain(domain): if 'amazon' in domain: return amazon_proxy_pool.get() elif 'google' in domain: return google_proxy_pool.get() else: return default_proxy_pool.get()
Recommended: Combine All Three
In real projects, layering strategies works best:
Request-level: Rotate every 50 requests
Time-level: Force rotation every 5 minutes
Domain-level: Different sites, different pools
Any trigger causes a rotation. Three layers of protection, ban rate drops to near zero.
4. The Step Most Tutorials Skip: Request Masking
Even the best proxies won't save you if your requests look like a bot.
Core Request Masking Elements
Element 1: User-Agent Rotation
Use a different UA for each request:
user_agents = [ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36', # ... more UAs ]def get_random_ua(): return random.choice(user_agents)
Don't just use 1-2 UAs. That's still obvious. Build a list of 20+ and refresh it regularly.
Element 2: Random Request Delays
Don't let your requests come at perfect intervals:
import random import timedef smart_sleep(): # Random delay between 1-3 seconds time.sleep(random.uniform(1, 3))
Note: Don't make delays too short (looks robotic) or too long (kills efficiency).
Element 3: Set the Referer Header
Simulate normal browsing behavior:
headers = { 'User-Agent': get_random_ua(), 'Referer': 'https://www.google.com/', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8', 'Accept-Language': 'en-US,en;q=0.5', }
Element 4: Cookie Management
Login-gated pages need session persistence:
session = requests.Session() session.cookies.update(login_and_get_cookies())
This makes your scraper look like a real human user.
5. The Step Most Tutorials Skip: Failure Handling
This is the final distinction between "works sometimes" and "rock solid."
Automatic Retry Logic
def fetch_with_retry(url, max_retries=3): for attempt in range(max_retries): try: proxy = get_next_proxy() response = requests.get(url, proxy=proxy, timeout=10)if response.status_code == 200: return response elif response.status_code == 403: # IP flagged—switch immediately mark_proxy_banned(proxy) continue else: return response except Exception as e: # Request failed—switch and retry mark_proxy_unavailable(proxy) continue return None</code></pre><h3>Proxy Health Checks</h3><p>Run periodic checks on your proxy pool:</p><pre><code class="language-python">def health_check(): for proxy in proxy_pool: try: response = requests.get('http://httpbin.org/ip', proxy=proxy, timeout=5) if response.status_code != 200: mark_proxy_unhealthy(proxy) except: mark_proxy_unhealthy(proxy)</code></pre><h3>Failover Strategy</h3><p>When your primary pool starts dying, switch to backup:</p><pre><code class="language-python">def get_proxy(): if primary_pool.available() > 10: return primary_pool.get() elif backup_pool.available() > 0: return backup_pool.get() else: # Wait for pool refresh wait_for_pool_refresh() return primary_pool.get()</code></pre><hr><h2>6. Anti-Ban Checklist</h2><p>Here's your complete checklist:</p><table style="min-width: 75px;"><colgroup><col style="min-width: 25px;"><col style="min-width: 25px;"><col style="min-width: 25px;"></colgroup><tbody><tr><th colspan="1" rowspan="1"><p>Check</p></th><th colspan="1" rowspan="1"><p>Description</p></th><th colspan="1" rowspan="1"><p>Done?</p></th></tr><tr><td colspan="1" rowspan="1"><p>✅ Right proxy type</p></td><td colspan="1" rowspan="1"><p>Residential for high-security sites</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Quality provider</p></td><td colspan="1" rowspan="1"><p>95%+ success rate, 5M+ pool</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Correct config format</p></td><td colspan="1" rowspan="1"><p>protocol://user:pass@addr:port</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Connection pool set up</p></td><td colspan="1" rowspan="1"><p>Reuse connections, boost efficiency</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Rotation strategy in place</p></td><td colspan="1" rowspan="1"><p>Request + time + domain level</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ UA rotation</p></td><td colspan="1" rowspan="1"><p>20+ UAs, refreshed regularly</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Random delays</p></td><td colspan="1" rowspan="1"><p>1-3 second random intervals</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Referer headers</p></td><td colspan="1" rowspan="1"><p>Simulate normal browsing</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Cookie handling</p></td><td colspan="1" rowspan="1"><p>Keep sessions alive on login pages</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Retry logic</p></td><td colspan="1" rowspan="1"><p>Auto-retry on failure, switch proxies</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Health checks</p></td><td colspan="1" rowspan="1"><p>Periodic proxy availability checks</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr><tr><td colspan="1" rowspan="1"><p>✅ Failover ready</p></td><td colspan="1" rowspan="1"><p>Backup pool when primary dies</p></td><td colspan="1" rowspan="1"><p>□</p></td></tr></tbody></table><hr><img class="rounded-md border border-border" src="https://data.ipipd.cn/common/image/2026/06/11/5cb62e98292b46d7937d5392bc2fedd1.jpg" alt="Complete anti-block guide including UA rotation, random delay, request header configuration, automatic retry & proxy health check mechanism, and full crawler anti-ban checklist." title="scraper-request-masking-failure-handling-anti-ban-checklist"><h2>7. Summary</h2><p>Five steps to build an unbannable scraper:</p><ol><li><p><strong>Pick the right proxy type</strong> — Residential for tough targets</p></li><li><p><strong>Configure proxies correctly</strong> — Connection pools + grouping</p></li><li><p><strong>Smart rotation strategies</strong> — Request + time + domain layers</p></li><li><p><strong>Request masking</strong> — UA rotation + delays + Referer + cookies</p></li><li><p><strong>Failure handling</strong> — Retry + health checks + failover</p></li></ol><p>Get these five right, and you're looking at 95%+ success rates.</p><blockquote><p>💡 <strong>Recommended tool:</strong> Need reliable proxy IPs? Try <a target="_blank" rel="noopener noreferrer nofollow" href="https://www.ipipd.com/en-US/pricing">IPIPD Residential Proxy</a>—195+ countries, 50M+ IPs, 95%+ success rate.</p></blockquote><hr><h2>8. Keep Reading</h2><ul><li><p><a target="_blank" rel="noopener noreferrer nofollow" href="https://www.ipipd.com/en-US/news/article/proxy-server-for-web-scraping">What Is a Proxy Server for Web Scraping? The Truth Nobody Tells You</a> — proxy basics</p></li><li><p><a target="_blank" rel="noopener noreferrer nofollow" href="https://www.ipipd.com/en-US/news/article/web-scraping-proxy-comparison">The Complete Web Scraping Proxy Solutions Comparison for 2026</a> — pick the right solution for your use case</p></li><li><p><a target="_blank" rel="noopener noreferrer nofollow" href="https://www.ipipd.com/en-US/news/article/web-scraping-proxy-tutorial">Web Scraping Proxy Setup: Build a High-Efficiency Data Collection System in 5 Minutes</a> — more hands-on tips</p></li></ul><hr>