代理服务器最佳实践:成功率95%和50%的差距在哪里
代理IP资讯2026-06-11T14:48:00
两个爬虫,用的是同一家代理服务商。
一个成功率95%,跑起来几乎不用管。
另一个成功率50%,天天被封,天天救火。
差距在哪?
不是工具问题,不是运气问题。是方法论问题。
今天这篇文章,把成功率95%和50%的差距彻底拆开给你看。

一、先看一组真实数据
在进入方法论之前,先看一组数据:
指标 | 成功率50%的做法 | 成功率95%的做法 |
|---|---|---|
代理类型 | 数据中心代理 | 住宅代理 |
IP轮换 | 偶尔换 | 自动化轮换 |
请求伪装 | 基本没有 | 完整伪装体系 |
常见问题
为什么爬虫成功率差距这么大?
成功率差距主要来自5个维度:1) 代理类型选择是否匹配目标网站;2) IP轮换是否自动化;3) 请求伪装是否完整;4) 失败处理是否有体系;5) 代理池是否有生命周期管理。做好这5点,成功率可以从50%提升到95%。
代理IP被封后应该怎么处理?
被封后分三步:1) 识别——判断是被封还是其他错误;2) 标记——将被封IP移出可用池;3) 切换——立即切换到下一个可用IP。同时要等封禁期结束后测试确认恢复,才能重新使用。
请求伪装有哪些关键要素?
四个关键要素:1) User-Agent轮换——准备50+个定期更新;2) 随机请求间隔——1-3秒随机;3) Referer头模拟——模拟从Google等页面跳转;4) 浏览器指纹——Canvas/WebGL指纹处理。
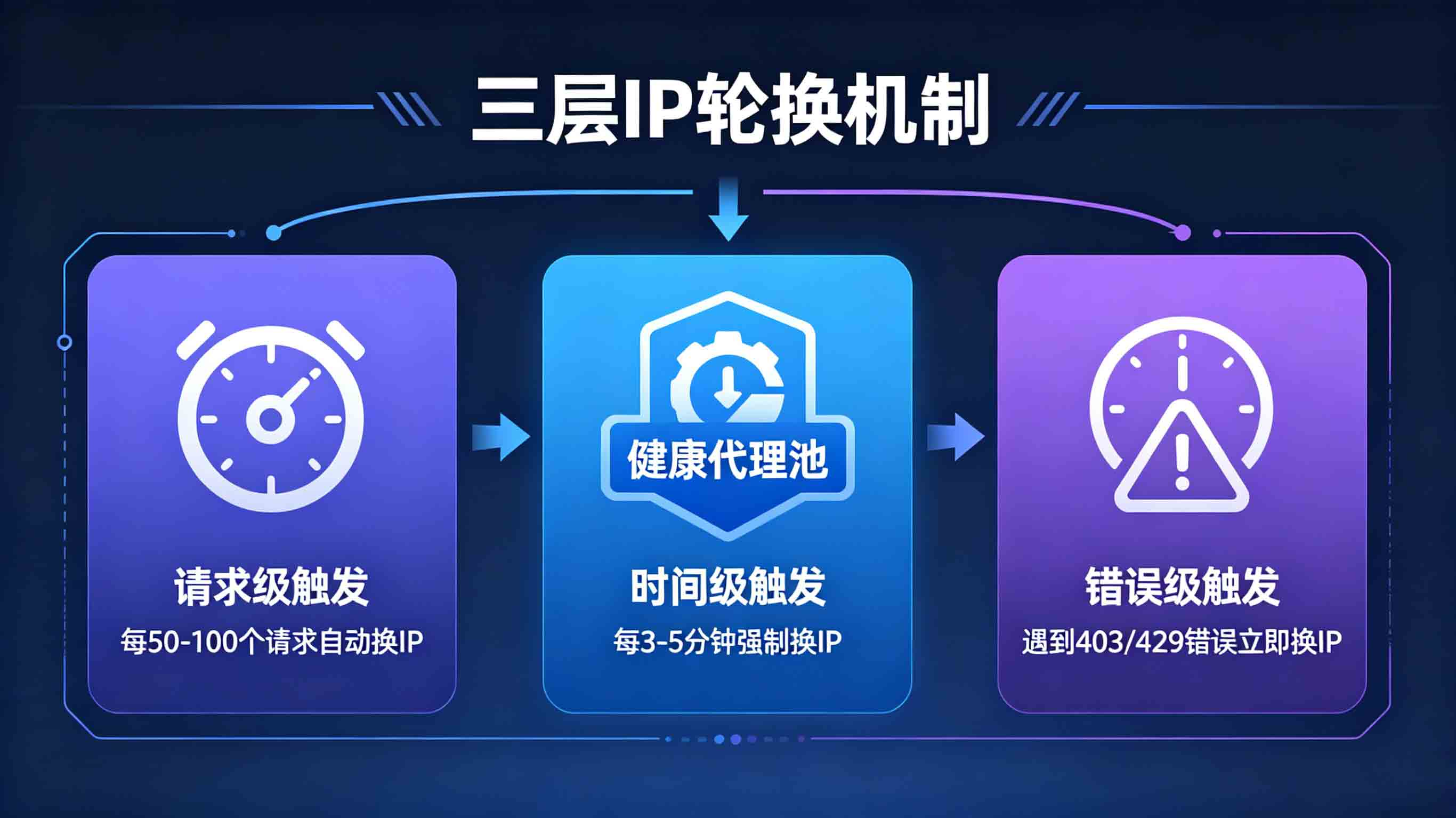
IP轮换有哪些策略?
三层触发机制:1) 请求级——每50-100个请求换一次;2) 时间级——每3-5分钟强制换一次;3) 错误级——遇到403/429立即换。三层叠加,任一触发都换。
